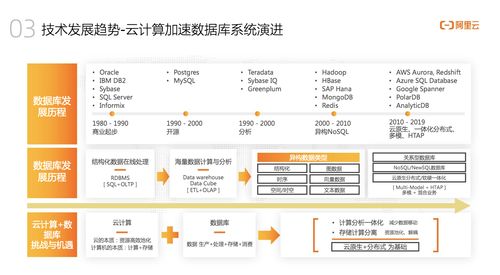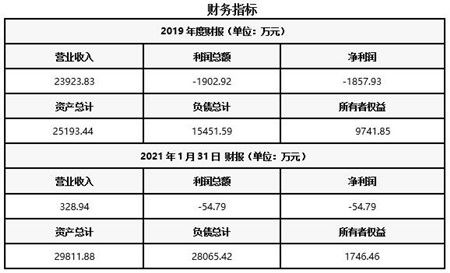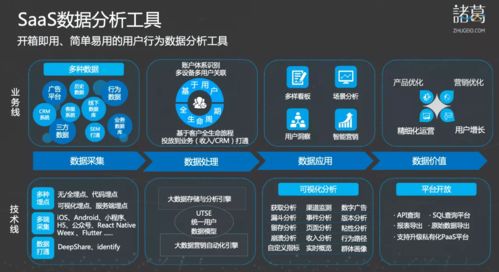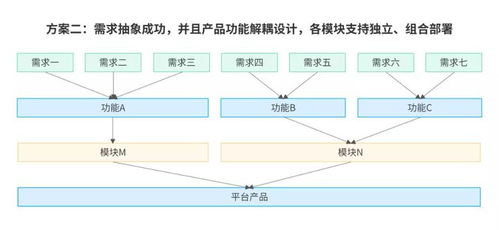
深度行情数据(Order Book Data),作为现代金融市场中最具价值的微观结构信息之一,为量化交易、市场微观结构研究、风险管理和监管科技提供了不可或缺的基础。对交易所深度行情数据的分析服务,其核心与基石在于高效、精准且可扩展的数据处理服务。本文旨在综述此类数据处理服务的关键环节、技术架构与未来趋势。
一、 深度行情数据的特征与处理挑战
交易所发布的原始深度行情数据流通常具有高频、海量、非结构化和瞬时变化的特征。一个典型的Tick数据流每秒可产生数千至上万笔更新,包含买卖各五档乃至全档位的价格、数量、订单号等信息。这给数据处理服务带来了多重挑战:
- 实时性要求:交易决策与风险监控往往需要在毫秒甚至微秒级别完成数据的接收、解析与计算。
- 高吞吐与低延迟:系统需具备极高的数据吞吐能力,并能将处理延迟降至最低。
- 数据一致性:在分布式处理环境中,保证订单簿状态重建的时序正确性和全局一致性是技术难点。
- 数据质量治理:需处理网络抖动导致的数据包丢失、交易所数据源本身的异常(如跳价、重复)等问题。
二、 数据处理服务的核心架构
一个成熟的深度行情数据处理服务通常采用分层、模块化的架构,主要包含以下核心组件:
- 数据采集与接入层:
- 多源适配:支持从交易所官方API、二进制协议、WebSocket、FIX协议等多种渠道实时接收数据。
- 连接管理:实现自动重连、心跳检测、流量控制,保证数据源的稳定连接。
- 协议解析:将原始的二进制或文本流快速反序列化为结构化的内存对象。
- 核心处理引擎层:
- 订单簿重建:这是最核心的模块。它根据逐笔成交和逐笔委托数据,在内存中动态维护一个或多个证券的实时订单簿快照。算法需高效处理订单的增、删、改操作。
- 指标实时计算:在订单簿快照基础上,实时计算买卖价差、市场深度、订单不平衡、加权平均报价、瞬时流动性等微观指标。
- 事件检测:识别大单冲击、冰山订单、价格跳跃、流动性枯竭等关键市场事件。
- 数据存储与查询层:
- 实时缓存:使用Redis、Memcached等内存数据库存储最新的订单簿快照和关键指标,供低延迟查询。
- 时序数据库:将计算出的指标和原始快照以时间序列形式写入如InfluxDB、DolphinDB、TDengine等数据库,支持高效的时间范围查询与聚合分析。
- 历史数据仓库:将清洗后的原始数据归档至HDFS、对象存储(如S3)或列式数据库(如ClickHouse),供离线大数据分析与模型训练。
- 服务与输出层:
- API服务:提供RESTful或gRPC接口,允许下游系统订阅特定证券的实时数据流或查询历史数据。
- 消息中间件:通过Kafka、Pulsar等将处理后的数据(如指标、事件)广播给多个消费方(如交易系统、风控系统、监控面板)。
- 数据可视化:为分析师提供实时订单簿盘口图、深度图、价量分布热力图等可视化工具。
三、 关键技术栈与优化策略
- 高性能编程:核心处理模块通常采用C++、Rust或Go等系统级语言编写,利用零拷贝、内存池、无锁数据结构等技术最大化单机性能。
- 并发与异步处理:广泛应用Actor模型、协程(如Goroutine)和异步I/O框架(如Netty、Tokio)来应对高并发数据流。
- 流处理框架:利用Flink、Spark Streaming或Kafka Streams等框架实现复杂的流上状态计算与窗口聚合,提升开发效率与系统容错性。
- 硬件加速:在极端低延迟场景下,可能采用FPGA或智能网卡(SmartNIC)进行网络包解析和初步过滤,将数据直接送达应用内存。
- 数据压缩:对传输中和存储中的数据进行高效压缩(如Zstandard、Snappy),以节省带宽与存储成本。
四、 未来发展趋势
- 云原生与微服务化:数据处理服务正朝着容器化、Kubernetes编排的方向发展,以实现弹性伸缩、高可用和敏捷部署。
- AI赋能的数据处理:引入机器学习模型进行实时数据异常检测、噪音过滤,甚至预测短期订单流,使数据处理从“描述”走向“预测”。
- 标准化与互操作性:随着跨市场、跨资产分析需求增长,对异构数据源的统一建模(如使用Apache Arrow内存格式)和标准化API接口的需求日益迫切。
- 合规与审计增强:数据处理链路需要内置更完善的审计追踪和数据溯源能力,以满足日益严格的金融监管要求。
结论
交易所深度行情数据分析服务的效能,根本上取决于其底层数据处理服务的先进性与可靠性。当前的技术架构已能有效应对高频数据的实时处理挑战,未来将继续向智能化、云原生化、标准化的方向演进。构建一个健壮的数据处理管道,不仅是挖掘市场阿尔法的基础,也是维护金融市场稳定与透明度的关键基础设施。对数据处理服务持续深入的研究与优化,将是金融科技领域一个长期而核心的议题。